Abstract
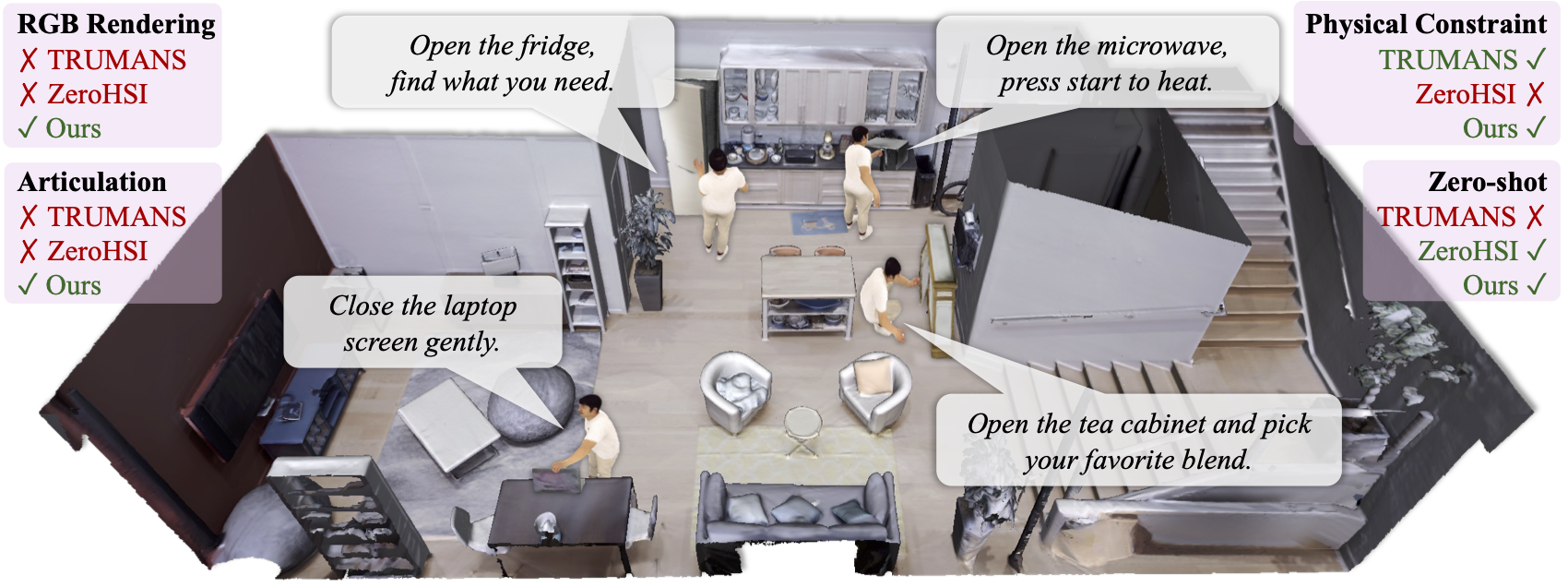
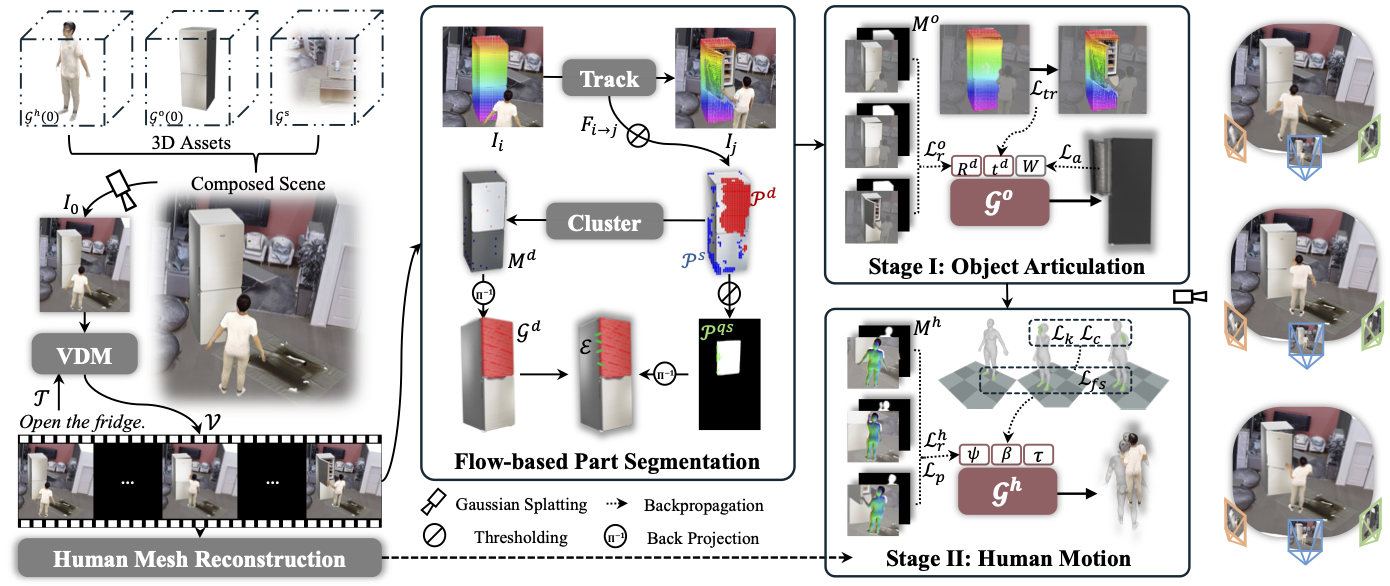
Synthesizing physically plausible articulated human-object interactions (HOI) without 3D/4D supervision remains a fundamental challenge. While recent zero-shot approaches leverage video diffusion models to synthesize human-object interactions, they are largely confined to rigid-object manipulation and lack explicit 4D geometric reasoning. To bridge this gap, we formulate articulated HOI synthesis as a 4D reconstruction problem from monocular video priors: given only a video generated by a diffusion model, we reconstruct a full 4D articulated scene without any 3D supervision. This reconstruction-based approach treats the generated 2D video as supervision for an inverse rendering problem, recovering geometrically consistent and physically plausible 4D scenes that naturally respect contact, articulation, and temporal coherence. We introduce ArtHOI, the first zero-shot framework for articulated human-object interaction synthesis via 4D reconstruction from video priors. Our key designs are: 1) Flow-based part segmentation: leveraging optical flow as a geometric cue to disentangle dynamic from static regions in monocular video; 2) Decoupled reconstruction pipeline: joint optimization of human motion and object articulation is unstable under monocular ambiguity, so we first recover object articulation, then synthesize human motion conditioned on the reconstructed object states. ArtHOI bridges video-based generation and geometry-aware reconstruction, producing interactions that are both semantically aligned and physically grounded. Across diverse articulated scenes (e.g., opening fridges, cabinets, microwaves), ArtHOI significantly outperforms prior methods in contact accuracy, penetration reduction, and articulation fidelity.